Kubernetes 网络问题排查
安全组
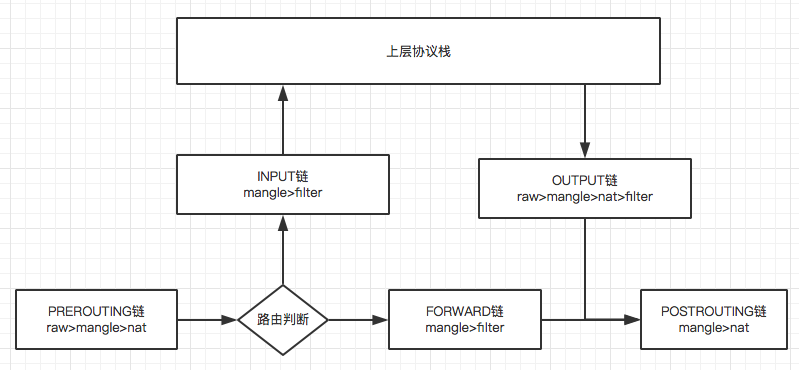
当一个网络包进入网卡的时候,首先拿下 mac 头看看是不是当前网卡的。
- 如果是,则拿下
IP头,得到了IP之后,就开始进行路由判断。在路由判断之前这个节点称为PREROUTING。 - 如果发现ip是当前网卡
IP,包就应该发给上面的传输层,这个节点叫做INPUT。 - 如果发现
IP不是当前网卡的,就需要进行转发,这个节点就叫FORWARD。 - 如果ip是当前网卡的
IP,则发送到上层处理。处理完一般会返回一个结果,把处理结果发出去,这个节点称为OUTPUT。 - 无论是
FORWARD和OUTPUT,都是在路由判断之后发生的,最有一个节点是POSTROUTING。
iptables 模块
在 Linux 内核中,有一个框架叫 Netfilter。可以在上面的几个节点放一个hook函数,这些函数可以对数据包进行干预。如果接受就是 ACCEPT;如果需要过滤掉就是 DROP;如果需要发送给用户态进程处理,就是 QUEUE。
iptables 就是实现了 Netfilter 框架,在上面五个节点上都放了hook函数,按照功能可以分为:
- conntrack: 连接跟踪
- filter: 数据包过滤
- nat: 网络地址转换
- mangle: 数据包修改
iptables
在用户态,有一个客户端程序 iptables,用命令行来干预内核的规则,内核的功能对于 iptables 来说,就是表和链的概念。
表
- raw
- mangle
- nat
- filter
优先级: raw > mangle > nat > filter
raw 不常用,主要功能都在剩下的几个表里面
filter 表
处理过滤功能
INPUT链: 过滤所有目标地址是本机的数据包FORWARD链: 过滤所有路过本机的数据包OUTPUT链: 过滤所有由本机产生的数据包
nat 表
PREROUTING链: 可以在数据包到达防火墙之前改变目标地址(DNT)OUTPUT链: 可以改变本地产生的数据包的目标地址POSTROUTING链: 在数据包离开防火墙时改变数据包的源地址(SNAT)
mangle 表
PREROUTING链INPUT链FORWARD链OUTPUT链POSTROUTING链
raw 表
PREROUTING链OUTPUT链
将 iptables 的表和链整合起来就形成了下面的图和过程。
Kubernetes 里的 Service
** Service 是由 kube-proxy 组件加上 iptables 来共同实现的**
iptables 模式
当我们创建的 service 提交到 Kubernetes 的时候,kube-proxy 就可以通过 Service 的 Informer 感知到 Service 对象添加。从而对这个事件进行响应,它会在宿主机上创建一条 iptables 规则。可以使用 iptables-save 看见这样一条规则:
1 | -A KUBE-SERVICES -d 10.27.248.11/32 -p tcp -m comment --comment "default/hostnames: cluster IP" -m tcp --dport 80 -j KUBE-SVC-NWV5X2332I4OT4T3 |
凡是目的地址是 10.27.248.11,端口号是80的包,都使用 KUBE-SVC-NWV5X2332I4OT4T3 iptables 链处理,而这个 10.27.248.11 这个就是 Service 的 clusterIP,在查看 KUBE-SVC-NWV5X2332I4OT4T3 规则,实际上是一组规则集合:
1 | -A KUBE-SVC-NWV5X2332I4OT4T3 -m comment --comment "default/hostnames:" -m statistic --mode random --probability 0.33332999982 -j KUBE-SEP-WNBA2IHDGP2BOBGZ |
这实际上是一组随机模式(–mode random)的 iptables 链,而 KUBE-SEP-(hash) 链指向的最终地址就是代理的三个 Pod(就是 Endpoint)。所以这一组规则就是 Service 实现负载均衡的位置。查看上述三条链明细,就能理解 Service 转发的具体原理:
1 | -A KUBE-SEP-57KPRZ3JQVENLNBR -s 10.28.1.123/32 -m comment --comment "default/hostnames:" -j MARK --set-xmark 0x00004000/0x00004000 |
这三条链其实就是三条 DNAT 规则。iptables 对流入的 IP 包还设置了一个标志(--set-xmark),在 PREROUTING 检查之前将流入 IP 包的目的地址和端口改成 --to-destination 所指定的新的地址和端口
IPVS 模式
基于 iptables 的 Service 实现,都是制约 Kubernetes 项目承载更多量级 Pod 的主要障碍,IPVS 并不需要在主机上为每个 Pod 设置 iptables 规则,而是把这些规则放到了内核态,从而极大地降低了维护这些规则的代价。IPVS 模式的工作原理,和 iptables 类似。当创建了 Service 后,kube-proxy 首先会在宿主机上创建一个虚拟网卡 kube-ipvs0。并为他分配 Service VIP 作为 IP 地址:
1 | ip addr |
然后 kube-proxy 就会通过 Linux 的 IPVS 模块,为这个IP地址设置三个 IPVS 虚拟主机,可以通过 ipvsadm 查看:
1 | ipvsadm -ln |
这三个 IPVS 虚拟主机的 IP 地址和端口对应的就是被代理的 Pod,之间使用轮询模式(rr)来作为负载均衡。
IPVS 模块只负责负载均衡和代理功能,而一个完整的 Service 流程正常工作需要的包过滤,SNAT,DNAT 等操作,还是要靠 iptables 来实现。只不过这些辅助性的 iptables 规则数量有限,也不会随着 Pod 数量增加而增加
查看 iptables nat 表
1 | -A PREROUTING -m comment --comment "kubernetes service portals" -j KUBE-SERVICES |
倒数第 3 条规则表示来源 IP 不是 10.27.248.0/22,则进入 KUBE-MARK-MASQ,打上 0x4000 标。倒数第 5 条规则就是在 POSTROUTING 的时候做 SNAT,如果看到有 0x4000 这个标志的,就修改来源 IP(MASQUERADE)。
SNAT 需要指定一个或多个 IP,MASQUERADE 不需要指定,直接获取网卡的 IP 作为来源 IP
问题和解决思路
Service 没办法通过 DNS 访问
区分到底是 Service 本身的配置问题还是集群的 DNS 除了问题,检查的有效方式就是 Kubernetes 自己的 master 节点的 Service DNS 是否正常:
1 | 在pod里面执行 |
如果执行有问题,那么就应该检查 kube-dns 的运行状态和日志。否则的话就应该检查 Service 定义是不是有问题。
Service 没办法通过 ClusterIP 访问
首先查看时候有 Endpoint(kubectl get endpoint xxxx),如果 Pod 的 readniessProbe 没有通过,也不会出现在 Endpoint 列表里面。如果 Endpoint 正常,就需要确认一下 kube-proxy 是否正确运行。如果 kube-proxy 一切正常,就应该查看宿主机的 iptables。
iptables 模式的话检查:
KUBE-SERVICE或者KUBE-NODEPORTS规则对应的入口链,这个规则应该和VIP和Service端口一一对应KUBE-SEP-(hash)规则对应的DNAT链,和Endpoint一一对应KUBE-SVC-(hash)规则对应负载均衡链,这些规则的数目应该和Endpoint数目对应- 如果是
NodePort模式的话,还有POSTROUTING的SNAT链
Pod 没办法通过 Service 访问自己
这往往就是因为 kubelet 的 hairpin-mode 没有正确被设置(Haripin Mode 发夹模式,在默认情况下,网桥设备是不允许一个数据包从一个端口进来,再从这个端口发出去,开启这个模式从而取消这个限制)
调试技巧
使用 nsenter 来进入 Pod 容器
1 | function e() { |
在需要调试的 Pod 的宿主机上先执行这个命令,然后使用 e pod-name namespaces 来进入 Pod 进行调试
真实案例复盘
现象
在集群内任意一个节点上访问 Service 的 cluster ip,如果这个 Service 的 Pod 运行在当前节点,则能访问成功,否则访问不成功
分析
在运行有 Pod 的宿主机上使用 tcpdump 抓 cni0 的包(cni0 和 eth0 做了桥接),发现包正常请求,正常返回
1 | tcpdump -nn -i cni0 tcp and host 10.28.248.11 |
分析:服务端是正常处理了请求的,应该是在返回的时候包被丢弃了(因为没有返回结果)。通过上面的 IPVS 模式的介绍,查看 iptables 的配置,发现了问题:
1 | pod ClusterCIDR: 10.28.0.0/16 |
而 iptables 处理的是非 10.28.0.0/16 的包才进行 SNAT,所以导致包回不去,被丢弃了。
解决办法
- 修改
ServiceCIDR为另外一个网段(推荐) - 每个宿主机上手动添加一条规则:
iptables -t nat -A POSTROUTING -s 10.28.0.0/16 -j SNAT --to-source 10.28.252.241(node ip)